Dazbo's GCP Skillsboost Challenge Lab Walkthroughs
My experience and walkthroughs with the GCP Skillsboost Challange Labs.
Generative AI with Vertex AI: Text Prompt Design
See Challenge Lab.
This lab is about designing and executing a number of generative AI prompts using Python, in a Jupyter notebook that is provided for you. The Jupyter notebook is incomplete, so your job is to complete the missing code. You will use the PaLM text bison LLM.
The entire lab can be done in about 10 minutes.
Useful Links
Google has dumped a load of prompt examples in this repo. You can get everything you need from here:
Generative AI Language Notebooks on GitHub
Tips
After completing each cell in the Jupyter notebook, press Shift-Enter to run that cell.
Objective
The goal is to complete missing code in the cells of a Jupyter notebook.
- Launch the Vertex AI Workbench JupyterLab Environment
- Load the Vertex AI language models
- Authenticate your environment
- Provide the Imports and Load the TextGenerationModel
- Demonstrate Prompt Design
- Demonstrate Ideation
- Demonstrate Text Classification
- Demonstrate Text Extraction
Launch the JupyterLab Environment
- Navigate to Vertex AI.
- Enable all recommendation APIs.
- Navigate to Workbench > User-managed notebooks > Open JupyterLag
- Open the Terminal from the Launcher pane of JupyterLab.
- Copy the notebook to the current folder:
gsutil cp gs://cloud-training/genai/palm_challenge_lab.ipynb . - Open the newly downloaded notebook:
Load the Vertex AI Language Models
# Complete the following pip command
!pip install google-cloud-aiplatform --upgrade --user
Authenticate Your Environment
Since we’re working in Vertex AI Workbench and not Colab, we don’t actually need to perform any authentication before initialising the VertexAI library. So you can skip this cell.
Provide the Imports and Load the TextGenerationModel
# Complete the two imports
from vertexai.preview.language_models import (ChatModel,
InputOutputTextPair,
TextEmbeddingModel,
TextGenerationModel
)
from IPython.display import Markdown, display
# Let's load the Text Generation LLM
TextGenerationModel.from_pretrained("text-bison@001")
Demonstrate Prompt Design
Create a prediction around the prompt, “Tell me about Google’s PaLM API.” Set the temperature for the least open ended response and set the max_output_tokens for the longest response possible with the text-bison@001 model. Leave the top_k and top_p with their defaults.
prompt = "Tell me about Google's PaLM API."
response = generation_model.predict(prompt=prompt,
temperature=1.0,
max_output_tokens=1024)
print(response.text)
Demonstrate Ideation
Use the below template to get your model to give you 5 title ideas for a training course on Google’s Generative AI technologies. Use display and Markdown to render the results.
prompt = "Generate five ideas for titles for a training course on Google's Generative AI technologies."
response = generation_model.predict(prompt)
display(Markdown(response.text))
Demonstrate Text Classification
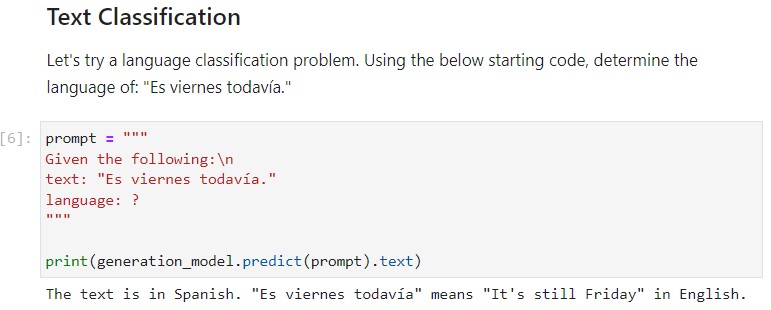
Let’s try a language classification problem. Using the below starting code, determine the language of: “Es viernes todavía.”
prompt = """
Given the following:\n
text: "Es viernes todavía."
language: ?
"""
print(generation_model.predict(prompt).text)
Now we turn the zero-shot prompt into a one-shot prompt by supplying an example of what we want the output to look like. We do this to reduce the response to one word: the language.
prompt = """
Given the following text, classify the language it is written in.
text: Darren loves a one-shot prompt
language: English
text: Es viernes todaví?
language:
"""
print(
generation_model.predict(
prompt=prompt,
).text
)
Demonstrate Text Extraction
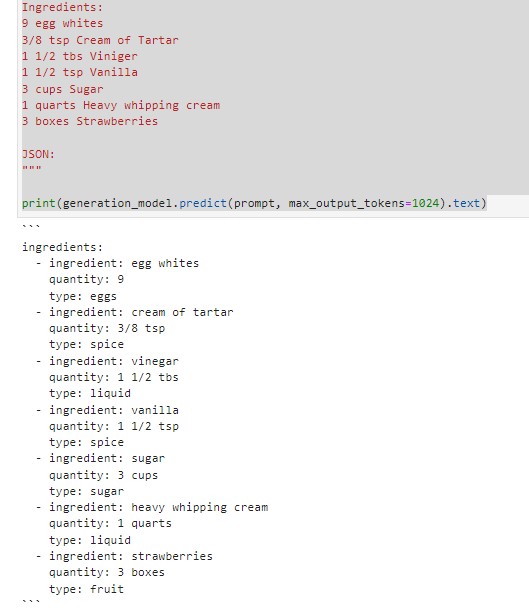
Convert the list of cooking ingredients to a YAML file with the keys: ingredient, quantity, type.
prompt = """
Extract the cooking ingredients from the text below,
and convert to a YAML file with keys of: ingredient, quantity, type.
Ingredients:
9 egg whites
3/8 tsp Cream of Tartar
1 1/2 tbs Viniger
1 1/2 tsp Vanilla
3 cups Sugar
1 quarts Heavy whipping cream
3 boxes Strawberries
JSON:
"""
print(generation_model.predict(prompt, max_output_tokens=1024).text)
Note that you need to change the number of output tokens, otherwise your YAML will be incomplete.